
Optical Character Recognition (OCR) for the Hindi Language (Single/Multiple files)


Optical character recognition or optical character reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten, or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo.

Now, one of the major features missing from the online(free) OCR tools is that they do not support multiple files upload. Imagine doing manual uploading of 100s of images, extracting the text, and then copy it to a text file. 😣🤯
Today we will be looking into Python implementation for two applications of OCR:
- OCR for the Hindi language implemented in Python using tesseract.
- OCR for multiple files present in the folder and creates individual/combined text files.
Let’s begin ⌛
Prerequisites:
Since we will be working with Python: the first requirement will be Python (better to have 3.6+). The other binaries will be as below:
1. Tesseract:
The heart of our program. As per Wikipedia, it is an OCR tool developed by HP and released to Open Source in 2005. You can download it here:
For Windows: Here
For Linux: Here
NOTE:
Please note that when asked to Choose components:
- Select Additional Script Data, expand it, and select Devanagari script.
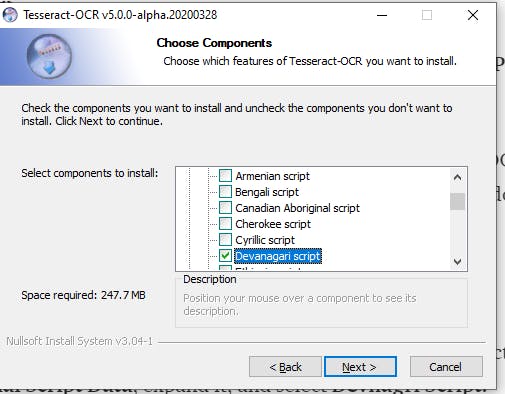
Additional Script Data -> Devanagari Script
- Under Additional Language Data, select Hindi.
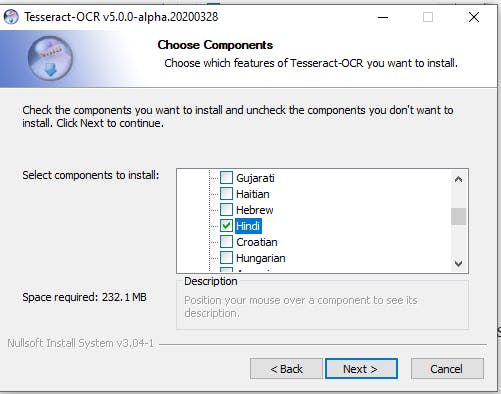
Additional Language Data -> Hindi
- Once installed, add the install location:
C:\Program Files\Tesseract-OCR(default for windows — at the time of writing this article) to the PATH variable.
2. Pillow:
Pillow is a fork for the Python Imaging Library. Install it using:
pip3 install pillow
3. Pytesseract:
Python-tesseract is an optical character recognition (OCR) tool for python.
pip3 install pytesseract
Time to code 👨🏽💻
#Python program to extract data from all the images present in the folder, and create a new file for each image
from PIL import Image
import pytesseract as pt
import os
def main():
# path for the folder for getting the raw images
path ="D:\\Images"
# path for the folder for getting the output
tempPath ="D:\\Images\\textFiles"
# iterating the images inside the folder
for imageName in os.listdir(path):
print ("-----------------------------")
inputPath = os.path.join(path, imageName)
img = Image.open(inputPath)
# applying ocr using pytesseract for python
text = pt.image_to_string(img, lang ="hin")
# for removing the .jpg from the imagePath
imageName = imageName[0:-4]
fullTempPath = os.path.join(tempPath, imageName+".txt")
print(text)
# saving the text for every image in a separate .txt file
file1 = open(fullTempPath, "w", encoding='utf-8')
file1.write(text)
file1.close()
if __name__ == '__main__':
main()